Как происходит обучение нейронной сети. Методы обучения нейронной сети
Добро пожаловать во вторую часть руководства по нейронным сетям. Сразу хочу принести извинения всем кто ждал вторую часть намного раньше. По определенным причинам мне пришлось отложить ее написание. На самом деле я не ожидал, что у первой статьи будет такой спрос и что так много людей заинтересует данная тема. Взяв во внимание ваши комментарии, я постараюсь предоставить вам как можно больше информации и в то же время сохранить максимально понятный способ ее изложения. В данной статье, я буду рассказывать о способах обучения/тренировки нейросетей (в частности метод обратного распространения) и если вы, по каким-либо причинам, еще не прочитали , настоятельно рекомендую начать с нее. В процессе написания этой статьи, я хотел также рассказать о других видах нейросетей и методах тренировки, однако, начав писать про них, я понял что это пойдет вразрез с моим методом изложения. Я понимаю, что вам не терпится получить как можно больше информации, однако эти темы очень обширны и требуют детального анализа, а моей основной задачей является не написать очередную статью с поверхностным объяснением, а донести до вас каждый аспект затронутой темы и сделать статью максимально легкой в освоении. Спешу расстроить любителей “покодить”, так как я все еще не буду прибегать к использованию языка программирования и буду объяснять все “на пальцах”. Достаточно вступления, давайте теперь продолжим изучение нейросетей.
Что такое нейрон смещения?

Перед тем как начать нашу основную тему, мы должны ввести понятие еще одного вида нейронов - нейрон смещения. Нейрон смещения или bias нейрон - это третий вид нейронов, используемый в большинстве нейросетей. Особенность этого типа нейронов заключается в том, что его вход и выход всегда равняются 1 и они никогда не имеют входных синапсов. Нейроны смещения могут, либо присутствовать в нейронной сети по одному на слое, либо полностью отсутствовать, 50/50 быть не может (красным на схеме обозначены веса и нейроны которые размещать нельзя). Соединения у нейронов смещения такие же, как у обычных нейронов - со всеми нейронами следующего уровня, за исключением того, что синапсов между двумя bias нейронами быть не может. Следовательно, их можно размещать на входном слое и всех скрытых слоях, но никак не на выходном слое, так как им попросту не с чем будет формировать связь.
Для чего нужен нейрон смещения?

Нейрон смещения нужен для того, чтобы иметь возможность получать выходной результат, путем сдвига графика функции активации вправо или влево. Если это звучит запутанно, давайте рассмотрим простой пример, где есть один входной нейрон и один выходной нейрон. Тогда можно установить, что выход O2 будет равен входу H1, умноженному на его вес, и пропущенному через функцию активации (формула на фото слева). В нашем конкретном случае, будем использовать сигмоид.
Из школьного курса математики, мы знаем, что если взять функцию y = ax+b и менять у нее значения “а”, то будет изменяться наклон функции (цвета линий на графике слева), а если менять “b”, то мы будем смещать функцию вправо или влево (цвета линий на графике справа). Так вот “а” - это вес H1, а “b” - это вес нейрона смещения B1. Это грубый пример, но примерно так все и работает (если вы посмотрите на функцию активации справа на изображении, то заметите очень сильное сходство между формулами). То есть, когда в ходе обучения, мы регулируем веса скрытых и выходных нейронов, мы меняем наклон функции активации. Однако, регулирование веса нейронов смещения может дать нам возможность сдвинуть функцию активации по оси X и захватить новые участки. Иными словами, если точка, отвечающая за ваше решение, будет находиться, как показано на графике слева, то ваша НС никогда не сможет решить задачу без использования нейронов смещения. Поэтому, вы редко встретите нейронные сети без нейронов смещения.
Также нейроны смещения помогают в том случае, когда все входные нейроны получают на вход 0 и независимо от того какие у них веса, они все передадут на следующий слой 0, но не в случае присутствия нейрона смещения. Наличие или отсутствие нейронов смещения - это гиперпараметр (об этом чуть позже). Одним словом, вы сами должны решить, нужно ли вам использовать нейроны смещения или нет, прогнав НС с нейронами смешения и без них и сравнив результаты.
ВАЖНО знать, что иногда на схемах не обозначают нейроны смещения, а просто учитывают их веса при вычислении входного значения например:
Input = H1*w1+H2*w2+b3
b3 = bias*w3
Так как его выход всегда равен 1, то можно просто представить что у нас есть дополнительный синапс с весом и прибавить к сумме этот вес без упоминания самого нейрона.
Как сделать чтобы НС давала правильные ответы?
Ответ прост - нужно ее обучать. Однако, насколько бы прост не был ответ, его реализация в плане простоты, оставляет желать лучшего. Существует несколько методов обучения НС и я выделю 3, на мой взгляд, самых интересных:- Метод обратного распространения (Backpropagation)
- Метод упругого распространения (Resilient propagation или Rprop)
- Генетический Алгоритм (Genetic Algorithm)
Что такое градиентный спуск?
Это способ нахождения локального минимума или максимума функции с помощью движения вдоль градиента. Если вы поймете суть градиентного спуска, то у вас не должно возникнуть никаких вопросов во время использования метода обратного распространения. Для начала, давайте разберемся, что такое градиент и где он присутствует в нашей НС. Давайте построим график, где по оси х будут значения веса нейрона(w) а по оси у - ошибка соответствующая этому весу(e).
Посмотрев на этот график, мы поймем, что график функция f(w) является зависимостью ошибки от выбранного веса. На этом графике нас интересует глобальный минимум - точка (w2,e2) или, иными словами, то место где график подходит ближе всего к оси х. Эта точка будет означать, что выбрав вес w2 мы получим самую маленькую ошибку - e2 и как следствие, самый лучший результат из всех возможных. Найти же эту точку нам поможет метод градиентного спуска (желтым на графике обозначен градиент). Соответственно у каждого веса в нейросети будет свой график и градиент и у каждого надо найти глобальный минимум.
Так что же такое, этот градиент? Градиент - это вектор который определяет крутизну склона и указывает его направление относительно какой либо из точек на поверхности или графике. Чтобы найти градиент нужно взять производную от графика по данной точке (как это и показано на графике). Двигаясь по направлению этого градиента мы будем плавно скатываться в низину. Теперь представим что ошибка - это лыжник, а график функции - гора. Соответственно, если ошибка равна 100%, то лыжник находиться на самой вершине горы и если ошибка 0% то в низине. Как все лыжники, ошибка стремится как можно быстрее спуститься вниз и уменьшить свое значение. В конечном случае у нас должен получиться следующий результат:

Представьте что лыжника забрасывают, с помощью вертолета, на гору. На сколько высоко или низко зависит от случая (аналогично тому, как в нейронной сети при инициализации веса расставляются в случайном порядке). Допустим ошибка равна 90% и это наша точка отсчета. Теперь лыжнику нужно спуститься вниз, с помощью градиента. На пути вниз, в каждой точке мы будем вычислять градиент, что будет показывать нам направление спуска и при изменении наклона, корректировать его. Если склон будет прямым, то после n-ого количества таких действий мы доберемся до низины. Но в большинстве случаев склон (график функции) будет волнистый и наш лыжник столкнется с очень серьезной проблемой - локальный минимум. Я думаю все знают, что такое локальный и глобальный минимум функции, для освежения памяти вот пример. Попадание в локальный минимум чревато тем, что наш лыжник навсегда останется в этой низине и никогда не скатиться с горы, следовательно мы никогда не сможем получить правильный ответ. Но мы можем избежать этого, снарядив нашего лыжника реактивным ранцем под названием момент (momentum). Вот краткая иллюстрация момента:

Как вы уже наверное догадались, этот ранец придаст лыжнику необходимое ускорение чтобы преодолеть холм, удерживающий нас в локальном минимуме, однако здесь есть одно НО. Представим что мы установили определенное значение параметру момент и без труда смогли преодолеть все локальные минимумы, и добраться до глобального минимума. Так как мы не можем просто отключить реактивный ранец, то мы можем проскочить глобальный минимум, если рядом с ним есть еще низины. В конечном случае это не так важно, так как рано или поздно мы все равно вернемся обратно в глобальный минимум, но стоит помнить, что чем больше момент, тем больше будет размах с которым лыжник будет кататься по низинам. Вместе с моментом в методе обратного распространения также используется такой параметр как скорость обучения (learning rate). Как наверняка многие подумают, чем больше скорость обучения, тем быстрее мы обучим нейросеть. Нет. Скорость обучения, также как и момент, является гиперпараметром - величина которая подбирается путем проб и ошибок. Скорость обучения можно напрямую связать со скоростью лыжника и можно с уверенностью сказать - тише едешь дальше будешь. Однако здесь тоже есть определенные аспекты, так как если мы совсем не дадим лыжнику скорости то он вообще никуда не поедет, а если дадим маленькую скорость то время пути может растянуться на очень и очень большой период времени. Что же тогда произойдет если мы дадим слишком большую скорость?

Как видите, ничего хорошего. Лыжник начнет скатываться по неправильному пути и возможно даже в другом направлении, что как вы понимаете только отдалит нас от нахождения правильного ответа. Поэтому во всех этих параметрах нужно находить золотую середину чтобы избежать не сходимости НС (об этом чуть позже).
Что такое Метод Обратного Распространения (МОР)?
Вот мы и дошли до того момента, когда мы можем обсудить, как же все таки сделать так, чтобы ваша НС могла правильно обучаться и давать верные решения. Очень хорошо МОР визуализирован на этой гифке:
А теперь давайте подробно разберем каждый этап. Если вы помните то в предыдущей статье мы считали выход НС. По другому это называется передача вперед (Forward pass), то есть мы последовательно передаем информацию от входных нейронов к выходным. После чего мы вычисляем ошибку и основываясь на ней делаем обратную передачу, которая заключается в том, чтобы последовательно менять веса нейронной сети, начиная с весов выходного нейрона. Значение весов будут меняться в ту сторону, которая даст нам наилучший результат. В моих вычисления я буду пользоваться методом нахождения дельты, так как это наиболее простой и понятный способ. Также я буду использовать стохастический метод обновления весов (об этом чуть позже).
Теперь давайте продолжим с того места, где мы закончили вычисления в предыдущей статье.
Данные задачи из предыдущей статьи

Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат - 0.33, ошибка - 45%.
Так как мы уже подсчитали результат НС и ее ошибку, то мы можем сразу приступить к МОРу. Как я уже упоминал ранее, алгоритм всегда начинается с выходного нейрона. В таком случае давайте посчитаем для него значение δ (дельта) по формуле 1.
 Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Таким образом наши вычисления для точки O1 будут выглядеть следующим образом.
Решение
O1output = 0.33
O1ideal = 1
Error = 0.45
δO1 = (1 - 0.33) * ((1 - 0.33) * 0.33) = 0.148
На этом вычисления для нейрона O1 закончены. Запомните, что после подсчета дельты нейрона мы обязаны сразу обновить веса всех исходящих синапсов этого нейрона. Так как в случае с O1 их нет, мы переходим к нейронам скрытого уровня и делаем тоже самое за исключение того, что формула подсчета дельты у нас теперь вторая и ее суть заключается в том, чтобы умножить производную функции активации от входного значения на сумму произведений всех исходящих весов и дельты нейрона с которой этот синапс связан. Но почему формулы разные? Дело в том что вся суть МОР заключается в том чтобы распространить ошибку выходных нейронов на все веса НС. Ошибку можно вычислить только на выходном уровне, как мы это уже сделали, также мы вычислили дельту в которой уже есть эта ошибка. Следственно теперь мы будем вместо ошибки использовать дельту которая будет передаваться от нейрона к нейрону. В таком случае давайте найдем дельту для H1:
Решение
H1output = 0.61
w5 = 1.5
δO1 = 0.148
δH1 = ((1 - 0.61) * 0.61) * (1.5 * 0.148) = 0.053
Теперь нам нужно найти градиент для каждого исходящего синапса. Здесь обычно вставляют 3 этажную дробь с кучей производных и прочим математическим адом, но в этом и вся прелесть использования метода подсчета дельт, потому что в конечном счете ваша формула нахождения градиента будет выглядеть вот так:
Здесь точка A это точка в начале синапса, а точка B на конце синапса. Таким образом мы можем подсчитать градиент w5 следующим образом:
Решение
H1output = 0.61
δO1 = 0.148
GRADw5 = 0.61 * 0.148 = 0.09
Сейчас у нас есть все необходимые данные чтобы обновить вес w5 и мы сделаем это благодаря функции МОР которая рассчитывает величину на которую нужно изменить тот или иной вес и выглядит она следующим образом:
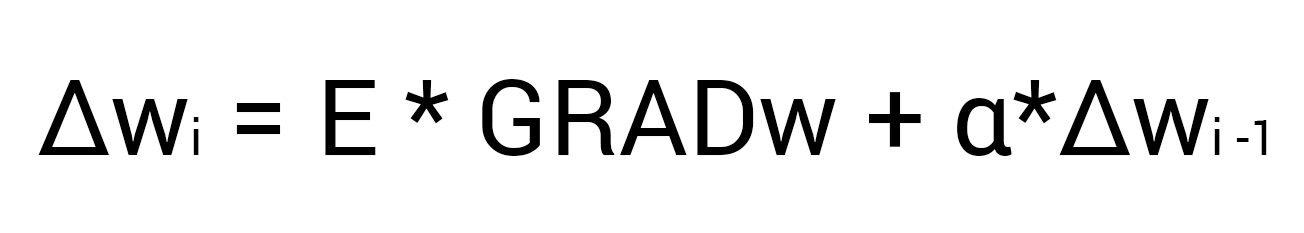
Настоятельно рекомендую вам не игнорировать вторую часть выражения и использовать момент так как это вам позволит избежать проблем с локальным минимумом.
Здесь мы видим 2 константы о которых мы уже говорили, когда рассматривали алгоритм градиентного спуска: E (эпсилон) - скорость обучения, α (альфа) - момент. Переводя формулу в слова получим: изменение веса синапса равно коэффициенту скорости обучения, умноженному на градиент этого веса, прибавить момент умноженный на предыдущее изменение этого веса (на 1-ой итерации равно 0). В таком случае давайте посчитаем изменение веса w5 и обновим его значение прибавив к нему Δw5.
Решение
E = 0.7
Α = 0.3
w5 = 1.5
GRADw5 = 0.09
Δw5(i-1) = 0
Δw5 = 0.7 * 0.09 + 0 * 0.3 = 0.063
w5 = w5 + Δw5 = 1.563
Таким образом после применения алгоритма наш вес увеличился на 0.063. Теперь предлагаю сделать вам тоже самое для H2.
Решение
H2output = 0.69
w6 = -2.3
δO1 = 0.148
E = 0.7
Α = 0.3
Δw6(i-1) = 0
δH2 = ((1 - 0.69) * 0.69) * (-2.3 * 0.148) = -0.07
GRADw6 = 0.69 * 0.148 = 0.1
Δw6 = 0.7 * 0.1 + 0 * 0.3 = 0.07
W6 = w6 + Δw6 = -2.2
И конечно не забываем про I1 и I2, ведь у них тоже есть синапсы веса которых нам тоже нужно обновить. Однако помним, что нам не нужно находить дельты для входных нейронов так как у них нет входных синапсов.
Решение
w1 = 0.45, Δw1(i-1) = 0
w2 = 0.78, Δw2(i-1) = 0
w3 = -0.12, Δw3(i-1) = 0
w4 = 0.13, Δw4(i-1) = 0
δH1 = 0.053
δH2 = -0.07
E = 0.7
Α = 0.3
GRADw1 = 1 * 0.053 = 0.053
GRADw2 = 1 * -0.07 = -0.07
GRADw3 = 0 * 0.053 = 0
GRADw4 = 0 * -0.07 = 0
Δw1 = 0.7 * 0.053 + 0 * 0.3 = 0.04
Δw2 = 0.7 * -0.07 + 0 * 0.3 = -0.05
Δw3 = 0.7 * 0 + 0 * 0.3 = 0
Δw4 = 0.7 * 0 + 0 * 0.3 = 0
W1 = w1 + Δw1 = 0.5
w2 = w2 + Δw2 = 0.73
w3 = w3 + Δw3 = -0.12
w4 = w4 + Δw4 = 0.13
Теперь давайте убедимся в том, что мы все сделали правильно и снова посчитаем выход НС только уже с обновленными весами.
Решение
I1 = 1
I2 = 0
w1 = 0.5
w2 = 0.73
w3 = -0.12
w4 = 0.13
w5 = 1.563
w6 = -2.2
H1input = 1 * 0.5 + 0 * -0.12 = 0.5
H1output = sigmoid(0.5) = 0.62
H2input = 1 * 0.73 + 0 * 0.124 = 0.73
H2output = sigmoid(0.73) = 0.675
O1input = 0.62* 1.563 + 0.675 * -2.2 = -0.51
O1output = sigmoid(-0.51) = 0.37
O1ideal = 1 (0xor1=1)
Error = ((1-0.37)^2)/1=0.39
Результат - 0.37, ошибка - 39%.
Как мы видим после одной итерации МОР, нам удалось уменьшить ошибку на 0.04 (6%). Теперь нужно повторять это снова и снова, пока ваша ошибка не станет достаточно мала.
Что еще нужно знать о процессе обучения?
Нейросеть можно обучать с учителем и без (supervised, unsupervised learning).Обучение с учителем - это тип тренировок присущий таким проблемам как регрессия и классификация (им мы и воспользовались в примере приведенном выше). Иными словами здесь вы выступаете в роли учителя а НС в роли ученика. Вы предоставляете входные данные и желаемый результат, то есть ученик посмотрев на входные данные поймет, что нужно стремиться к тому результату который вы ему предоставили.
Обучение без учителя - этот тип обучения встречается не так часто. Здесь нет учителя, поэтому сеть не получает желаемый результат или же их количество очень мало. В основном такой вид тренировок присущ НС у которых задача состоит в группировке данных по определенным параметрам. Допустим вы подаете на вход 10000 статей на хабре и после анализа всех этих статей НС сможет распределить их по категориям основываясь, например, на часто встречающихся словах. Статьи в которых упоминаются языки программирования, к программированию, а где такие слова как Photoshop, к дизайну.
Существует еще такой интересный метод, как обучение с подкреплением (reinforcement learning). Этот метод заслуживает отдельной статьи, но я попытаюсь вкратце описать его суть. Такой способ применим тогда, когда мы можем основываясь на результатах полученных от НС, дать ей оценку. Например мы хотим научить НС играть в PAC-MAN, тогда каждый раз когда НС будет набирать много очков мы будем ее поощрять. Иными словами мы предоставляем НС право найти любой способ достижения цели, до тех пор пока он будет давать хороший результат. Таким способом, сеть начнет понимать чего от нее хотят добиться и пытается найти наилучший способ достижения этой цели без постоянного предоставления данных “учителем”.
Также обучение можно производить тремя методами: стохастический метод (stochastic), пакетный метод (batch) и мини-пакетный метод (mini-batch). Существует очень много статей и исследований на тему того, какой из методов лучше и никто не может прийти к общему ответу. Я же сторонник стохастического метода, однако я не отрицаю тот факт, что каждый метод имеет свои плюсы и минусы.
Вкратце о каждом методе:
Стохастический (его еще иногда называют онлайн) метод работает по следующему принципу - нашел Δw, сразу обнови соответствующий вес.
Пакетный метод же работает по другому. Мы суммируем Δw всех весов на текущей итерации и только потом обновляем все веса используя эту сумму. Один из самых важных плюсов такого подхода - это значительная экономия времени на вычисление, точность же в таком случае может сильно пострадать.
Мини-пакетный метод является золотой серединой и пытается совместить в себе плюсы обоих методов. Здесь принцип таков: мы в свободном порядке распределяем веса по группам и меняем их веса на сумму Δw всех весов в той или иной группе.
Что такое гиперпараметры?
Гиперпараметры - это значения, которые нужно подбирать вручную и зачастую методом проб и ошибок. Среди таких значений можно выделить:- Момент и скорость обучения
- Количество скрытых слоев
- Количество нейронов в каждом слое
- Наличие или отсутствие нейронов смещения
Что такое сходимость?

Сходимость говорит о том, правильная ли архитектура НС и правильно ли были подобраны гиперпараметры в соответствии с поставленной задачей. Допустим наша программа выводит ошибку НС на каждой итерации в лог. Если с каждой итерацией ошибка будет уменьшаться, то мы на верном пути и наша НС сходится. Если же ошибка будет прыгать вверх - вниз или застынет на определенном уровне, то НС не сходится. В 99% случаев это решается изменением гиперпараметров. Оставшийся 1% будет означать, что у вас ошибка в архитектуре НС. Также бывает, что на сходимость влияет переобучение НС.
Что такое переобучение?
Переобучение, как следует из названия, это состояние нейросети, когда она перенасыщена данными. Это проблема возникает, если слишком долго обучать сеть на одних и тех же данных. Иными словами, сеть начнет не учиться на данных, а запоминать и “зубрить” их. Соответственно, когда вы уже будете подавать на вход этой НС новые данные, то в полученных данных может появиться шум, который будет влиять на точность результата. Например, если мы будем показывать НС разные фотографии яблок (только красные) и говорить что это яблоко. Тогда, когда НС увидит желтое или зеленое яблоко, оно не сможет определить, что это яблоко, так как она запомнила, что все яблоки должны быть красными. И наоборот, когда НС увидит что-то красное и по форме совпадающее с яблоком, например персик, она скажет, что это яблоко. Это и есть шум. На графике шум будет выглядеть следующим образом.
Видно, что график функции сильно колеблется от точки к точке, которые являются выходными данными (результатом) нашей НС. В идеале, этот график должен быть менее волнистый и прямой. Чтобы избежать переобучения, не стоит долго тренировать НС на одних и тех же или очень похожих данных. Также, переобучение может быть вызвано большим количеством параметров, которые вы подаете на вход НС или слишком сложной архитектурой. Таким образом, когда вы замечаете ошибки (шум) в выходных данных после этапа обучения, то вам стоит использовать один из методов регуляризации, но в большинстве случаев это не понадобиться.
Заключение
Надеюсь эта статья смогла прояснить ключевые моменты такого нелегко предмета, как Нейронные сети. Однако я считаю, что сколько бы ты статей не прочел, без практики такую сложную тему освоить невозможно. Поэтому, если вы только в начале пути и хотите изучить эту перспективную и развивающуюся отрасль, то советую начать практиковаться с написания своей НС, а уже после прибегать к помощи различных фреймворков и библиотек. Также, если вам интересен мой метод изложения информации и вы хотите, чтобы я написал статьи на другие темы связанные с Машинным обучением, то проголосуйте в опросе ниже за ту тему которую вам интересна. До встречи в будущих статьях:)Только зарегистрированные пользователи могут участвовать в опросе. Войдите , пожалуйста.
Самым важным свойством нейронных сетей является их способность обучаться на основе данных окружающей среды и в результате обучения повышать свою производительность. Повышение производительности происходит со временем в соответствии с определенными правилами. Обучение нейронной сети происходит посредством интерактивного процесса корректировки синаптических весов и порогов. В идеальном случае нейронная сеть получает знания об окружающей среде на каждой итерации процесса обучения.
С понятием обучения ассоциируется довольно много видов деятельности, поэтому сложно дать этому процессу однозначное определение. Более того, процесс обучения зависит от точки зрения на него. Именно это делает практически невозможным появление какого-либо точного определения этого понятия. Например, процесс обучения с точки зрения психолога в корне отличается от обучения с точки зрения школьного учителя. С позиций нейронной сети, вероятно, можно использовать следующее определение:
Обучение – это процесс, в котором свободные параметры нейронной сети настраиваются посредством моделирования среды, в которую эта сеть встроена. Тип обучения определяется способом подстройки этих параметров.
Это определение процесса обучения нейронной сети предполагает следующую последовательность событий:
- В нейронную сеть поступают стимулы из внешней среды.
- В результате первого пункта изменяются свободные параметры нейронной сети.
- После изменения внутренней структуры нейронная сеть отвечает на возбуждения уже иным образом.
Вышеуказанный список четких правил решения проблемы обучения нейронной сети называется алгоритмом обучения. Несложно догадаться, что не существует универсального алгоритма обучения, подходящего для всех архитектур нейронных сетей. Существует лишь набор средств, представленный множеством алгоритмов обучения, каждый из которых имеет свои достоинства. Алгоритмы обучения отличаются друг от друга способом настройки синаптических весов нейронов. Еще одной отличительной характеристикой является способ связи обучаемой нейронной сети с внешним миром. В этом контексте говорят о парадигме обучения, связанной с моделью окружающей среды, в которой функционирует данная нейронная сеть.
Существуют два концептуальных подхода к обучению нейронных сетей: обучение с учителем и обучение без учителя.
Обучение нейронной сети с учителем предполагает, что для каждого входного вектора из обучающего множества существует требуемое значение выходного вектора, называемого целевым. Эти вектора образуют обучающую пару. Веса сети изменяют до тех пор, пока для каждого входного вектора не будет получен приемлемый уровень отклонения выходного вектора от целевого.
Обучение нейронной сети без учителя является намного более правдоподобной моделью обучения с точки зрения биологических корней искусственных нейронных сетей. Обучающее множество состоит лишь из входных векторов. Алгоритм обучения нейронной сети подстраивает веса сети так, чтобы получались согласованные выходные векторы, т.е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы.
Итак, сегодня мы продолжим обсуждать тему нейронных сетей на нашем сайте, и, как я и обещал в первой статье (), речь пойдет об обучении сетей . Тема эта очень важна, поскольку одним из основных свойств нейронных сетей является именно то, что она не только действует в соответствии с каким-то четко заданным алгоритмом, а еще и совершенствуется (обучается) на основе прошлого опыта. И в этой статье мы рассмотрим некоторые формы обучения, а также небольшой практический пример.
Давайте для начала разберемся, в чем же вообще состоит цель обучения. А все просто – в корректировке весовых коэффициентов связей сети. Одним из самых типичных способов является управляемое обучение . Для его проведения нам необходимо иметь набор входных данных, а также соответствующие им выходные данные. Устанавливаем весовые коэффициенты равными некоторым малым величинам. А дальше процесс протекает следующим образом…
Мы подаем на вход сети данные, после чего сеть вычисляет выходное значение. Мы сравниваем это значение с имеющимся у нас (напоминаю, что для обучения используется готовый набор входных данных, для которых выходной сигнал известен) и в соответствии с разностью между этими значениями корректируем весовые коэффициенты нейронной сети. И эта операция повторяется по кругу много раз. В итоге мы получаем обученную сеть с новыми значениями весовых коэффициентов.
Вроде бы все понятно, кроме того, как именно и по какому алгоритму необходимо изменять значение каждого конкретного весового коэффициента. И в сегодняшней статье для коррекции весов в качестве наглядного примера мы рассмотрим правило Видроу-Хоффа , которое также называют дельта-правилом .
Дельта правило (правило Видроу-Хоффа).
Определим ошибку :
Здесь у нас – это ожидаемый (истинный) вывод сети, а – это реальный вывод (активность) выходного элемента. Помимо выходного элемента ошибки можно определить и для всех элементов скрытого слоя нейронной сети, об этом мы поговорим чуть позже.
Дельта-правило заключается в следующем – изменение величины весового коэффициента должно быть равно:
Где – норма обучения. Это число мы сами задаем перед началом обучения. – это сигнал, приходящий к элементу k от элемента j . А – ошибка элемента k .
Таким образом, в процессе обучения на вход сети мы подаем образец за образцом, и в результате получаем новые значения весовых коэффициентов. Обычно обучение заканчивается когда для всех вводимых образцов величина ошибки станет меньше определенной величины. После этого сеть подвергается тестированию при помощи новых данных, которые не участвовали в обучении. И по результатам этого тестирования уже можно сделать выводы, хорошо или нет справляется сеть со своими задачами.
С корректировкой весов все понятно, осталось определить, каким именно образом и по какому алгоритму будут происходить расчеты при обучении сети. Давайте рассмотрим обучение по алгоритму обратного распространения ошибок.
Алгоритм обратного распространения ошибок.
Этот алгоритм определяет два “потока” в сети. Входные сигналы двигаются в прямом направлении, в результате чего мы получаем выходной сигнал, из которого мы получаем значение ошибки. Величина ошибки двигается в обратном направлении, в результате происходит корректировка весовых коэффициентов связей сети. В конце статьи мы рассмотрим пример, наглядно демонстрирующий эти процессы.
Итак, для корректировки весовых значений мы будем использовать дельта-правило, которое мы уже обсудили. Вот только необходимо определить универсальное правило для вычисления ошибки каждого элемента сети после, собственно, прохождения через элемент (при обратном распространении ошибок).
Я, пожалуй, не буду приводить математические выводы и расчеты (несмотря на мою любовь к математике 🙂), чтобы не перегружать статью, ограничимся только итоговыми результатами:

Функция – это функция активности элемента. Давайте использовать логистическую функцию, для нее:
Подставляем в предыдущую формулу и получаем величину ошибки:
В этой формуле:
Наверняка сейчас еще все это кажется не совсем понятным, но не переживайте, при рассмотрении практического примера все встанет на свои места 😉
Собственно, давайте к нему и перейдем.
Перед обучением сети необходимо задать начальные значения весов – обычно они инициализируются небольшими по величине случайными значениями, к примеру из интервала (-0.5, 0.5). Но для нашего примера возьмем для удобства целые числа.
Рассмотрим нейронную сеть и вручную проведем расчеты для прямого и обратного “потоков” в сети.

На вход мы должны подать образец, пусть это будет (0.2, 0.5) . Ожидаемый выход сети – 0.4 . Норма обучения пусть будет равна 0.85 . Давайте проведем все расчеты поэтапно. Кстати, совсем забыл, в качестве функции активности мы будем использовать логистическую функцию:

Итак, приступаем…
Вычислим комбинированный ввод элементов 2 , 3 и 4 :
Активность этих элементов равна:
Комбинированный ввод пятого элемента:
Активность пятого элемента и в то же время вывод нейронной сети равен:
С прямым “потоком” разобрались, теперь перейдем к обратному “потоку”. Все расчеты будем производить в соответствии с формулами, которые мы уже обсудили. Итак, вычислим ошибку выходного элемента:
Тогда ошибки для элементов 2 , 3 и 4 равны соответственно:
Здесь значения -0.014, -0.028 и -0.056 получаются в результате прохода ошибки выходного элемента –0.014 по взвешенным связям в направлении к элементам 2 , 3 и 4 соответственно.
И, наконец-то, рассчитываем величину, на которую необходимо изменить значения весовых коэффициентов. Например, величина корректировки для связи между элементами 0 и 2 равна произведению величины сигнала, приходящего в элементу 2 от элемента 0 , ошибки элемента 2 и нормы обучения (все по дельта-правилу, которое мы обсудили в начале статьи):
Аналогичным образом производим расчеты и для остальных элементов:
Теперь новые весовые коэффициенты будут равны сумме предыдущего значения и величины поправки.
На этом обратный проход по сети закончен, цель достигнута 😉 Именно так и протекает процесс обучения по алгоритму обратного распространения ошибок. Мы рассмотрели этот процесс для одного набора данных, а чтобы получить полностью обученную сеть таких наборов должно быть, конечно же, намного больше, но алгоритм при этом остается неизменным, просто повторяется по кругу много раз для разных данных)
По просьбе читателей блога я решил добавить краткий пример обучения сети с двумя скрытыми слоями:

Итак, добавляем в нашу сеть два новых элемента (X и Y), которые теперь будут выполнять роль входных. На вход также подаем образец (0.2, 0.5) . Рассмотрим алгоритм в данном случае:
1. Прямой проход сети. Здесь все точно также как и для сети с одним скрытым слоем. Результатом будет значение .
2. Вычисляем ошибку выходного элемента:
3. Теперь нам нужно вычислить ошибки элементов 2, 3 и 4.
Методы, правила и алгоритмы, применяемые при обучении различных топологий сетей.
. Обучение нейронных сетей.
. Методы обучения нейронных сетей .
Решение задачи на нейрокомпьютере принципиально отличается от решения той же задачи на обычной ЭВМ с Фон-Неймановской архитектурой. Решение задачи на обычной ЭВМ заключается в обработке вводимых данных в соответствии с программой. Программу составляет человек. Для составления программы нужно придумать алгоритм, т.е. определенную последовательность математических и логических действий, необходимых для решения этой задачи. Алгоритмы, как и программы, разрабатываются людьми, а компьютер используется лишь для выполнения большого количества элементарных операций: сложения, умножения, проверки логических условий и т.п.
Нейрокомпьютер же используется как “ черный ящик”, который можно обучить решению задач из какого-нибудь класса. Нейрокомпьютеру “предъявляются” исходные данные задачи и ответ, который соответствует этим данным и который был получен каким-либо способом. Нейрокомпьютер должен сам построить внутри “черного ящика” алгоритм решения этой задачи, чтобы выдавать ответ, совпадающий с правильным. Кажется естественным ожидать, что чем больше различных пар (исходных данных), (ответ) , будет предъявлено нейрокомпьютеру, тем адекватнее решаемой задаче он сконструирует модель.
После этапа обучения нейрокомпьютера следует надеяться, что если ему предъявить исходные данные, которых он раньше не встречал, он тем не менее выдает правильное решение - в этом заключается способность нейрокомпьютера к обобщению.
Поскольку в основе нейрокомпьютера лежит искусственная нейронная сеть, то процесс обучения состоит в настройке параметров это сети. При этом, как правило, топология сети считается неизменной, а к подстраиваемым параметрам обычно относятся параметры нейронов и величины синаптических весов. К настоящему моменту в литературе принято под обучением понимать процесс изменения весов связей между нейронами.
Мы рассмотрим два направления классификации методов обучения сетей. Первое направление - по способам использования учителя.
С учителем:
Cети предъявляются примеры входных данных и выходных. Сеть преобразует входные данные и сравнивает свой выход с желаемым. После этого проводится коррекция весов с целью получить лучшую согласованность выходов.
Обучение с последовательным подкреплением знаний:
В этом случае сети не дается желаемое значение выхода, а вместо этого сети ставится оценка, хорош выход или плох.
Обучение без учителя:
Сеть сама вырабатывает правила обучения путем выделения особенностей из набора входных данных.
Второе направление классификации методов обучения - по использованию элементов случайности.
Детерминистские методы:
В них шаг за шагом осуществляется процедура коррекции весов сети, основанная на использовании текущих их значений, например значений желаемых выходов сети. Рассматриваемый далее алгоритм обучения, основанный на обратном распространении ошибки, является примером детерминистского обучения.
Стохастические методы обучения:
Они основываются на использовании случайных изменений весов в ходе обучения. Рассматриваемый далее алгоритм Больцмановского обучения является примером стохастического обучения.
. Правила обучения нейросетей .
Правила обучения определяют закон, по которому сеть должна изменить свои синаптические веса в процессе обучения.
Правило Хебба (D.Hebb):
Большинство методов обучения основываются на общих принципах обучения нейросетей, развитых Дональдом Хеббом . Принцип Хебба можно сформулировать следующим образом: “ Если два нейрона одновременно активны, увеличьте силу связи между ними “, что можно записать как:
dW ij = gf (Y i) f(Y j) ,
где: dW ij - величина изменения синапса W ij
Y i - уровень возбуждения i-го нейрона
Y j - уровень возбуждения j-го нейрона
f(.) - преобразующая функция
g - константа, определяющая скорость обучения.
Большинство обучающих правил основаны на этой формуле.
Дельта-правило:
Оно известно как правило снижения квадратичной ошибки и было предложено . Дельта-правило используется при обучении с учителем.
dW ij = g (D j - Y j) Y i
где: D j - желаемый выход j-го нейрона.
Таким образом, изменение силы связей происходит в соответствии с ошибкой выходного сигнала (D j - Y j) и уровнем активности входного элемента Y. Обобщение дельта-правила, называемое обратным распространением ошибки(Back-Propagation), используется в НС с двумя и более слоями.
ART - правило:
Теория адаптивного резонанса (ART) была развита в . ART - это обучение без учителя, когда самоорганизация происходит в результате отклика на выбор входных образов. ART- сеть способна к классификации образов. ART использует концепцию долговременной и кратковременной памяти для обучения НС. В долговременной памяти хранятся реакции на образы, которым сеть была обучена, в виде векторов весов. В кратковременную память помещается текущий входной образ, ожидаемый образ, классификация входного образа. Ожидаемый образ выбирается из долговременной памяти всякий раз, когда на вход НС подается новый паттерн. Если они схожи в соответствии с определенным критерием, сеть классифицирует его как принадлежащий к существующему классу. Если они различны, формируется новый класс, в котором входной вектор будет первым членом класса.
Такое обучение называют состязательным обучением. Простейший тип состязательного обучения определяется правилом “победитель берет все“, т.е. ансамбль с лучшим выходом активизируется, остальные - подавляются.
Элемент с наибольшим уровнем активации называют “победитель”. Когда он выбран, НС добавляет черты вводимого образа в члены долговременной памяти путем повторного прогона вперед - назад через веса долговременной памяти. Этот процесс Гроссберг назвал резонансом.
Правило Кохонена:
Тео Кохонен из Хельсинского технологического института использовал концепцию состязательного обучения для развития обучающего правила ” без учителя “ в НС типа карты Кохонена (рис.3.3).
Правило Кохонена заключается в следующем. Сначала выбирается победитель по стратегии “ победитель берет все ”. Поскольку выход j-го нейрона определяется скалярным произведением (U,W j) входного вектора U с вектором весов связей между входным слоем и j-м нейроном, то он зависит от угла между векторами U,W j . Поэтому выбирается нейрон, вектор весов W j которого наиболее близок ко входному вектору U. (другими словами, выбирается наиболее активный нейрон). Далее конструируется новый вектор W j так, чтобы он был ближе ко входному вектору U, т.е. :
W ij new = W ij old + g (U - W ij old) i = 1,2,...,k.
где: k - количество входов сети.
g - константа обучения.
Больцмановское обучение:
Больцмановское обучение состоит в подкреплении обученности в соответствии с целевой функцией изменения выхода НС. Это обучение использует вероятностную функцию для изменения весов. Эта функция обычно имеет вид распределения Гаусса, хотя могут использоваться и другие распределения.
Больцмановское обучение выполняется в несколько этапов.
1. Коэффициенту T присваивают большое начальные значение.
2. Через сеть пропускают входной вектор,и по выходу вычисляют целевую функцию.
3. Случайным образом изменяют вес в соответствии с распределением Гаусса: P(x)=exp(-x 2 /T 2) ,где x - изменение веса.
4. Снова вычисляют выход и целевую функцию.
5. Если значение целевой функции уменьшилось (улучшилось) , то сохраняют изменение веса. Если же нет и величина ухудшения целевой функции составляет С, то вероятность сохранения изменения веса вычисляется следующим образом.
Величина Р(С) - вероятность изменения С в целевой функции, определяется с использованием распределения Больцмана: P(С)~exp(- С/kT)
где: k - константа, аналогичная константе Больцмана, выбирается в зависимости от условий задачи.
Затем выбирают случайное число V ,используя равномерное распределение от нуля до единицы. Если Р(С)>V , то изменение веса сохраняется иначе изменение веса равно нулю.
Шаги 3 - 5 повторяют для каждого из весов сети, при этом постепенно уменьшают T , пока не будет достигнуто приемлемо низкое значение целевой функции. После этого повторяют весь процесс обучения для другого входного вектора. Сеть обучается на всех векторах, пока целевая функция не станет допустимой для всех них. При этом для обеспечения сходимости изменение T должно быть пропорциональным логарифму времени t :
T(t) = T(0) / log(1+t)
Это означает, что скорость сходимости целевой функции невелика, следовательно,время обучения может быть очень большим.
. Алгоритмы обучения нейросетей.
Обучение сетей прямого распространения.
Для обучения сети нужно знать значения d j (j=1,2 . . .n(K)) выходов с нейронов выходного слоя (желаемые выходы) , которые сеть должна выдавать при поступлении на ее вход возбуждающего вектора I .
Ошибка функционирования сети на этих данных определяется как
где: y j - выход сети.
Для уменьшения этой ошибки следует изменить веса сети по следующему правилу:
W k new = W k old - (E/ W k)
где: - константа, характеризующая скорость обучения.
Последняя формула описывает процесс градиентного спуска в пространстве весов. Выражение для производной dE/dW имеет следующий вид:
E/W k-1 ij = (d j - y j) f j u k-1 i для выходного слоя, т.е. k = K
E/W k-1 ij =[ (d j - y j) f j w k ij ] f j u k-1 i для скрытых слоев,
т.е. k=1,2 . . . , K-1.
Если в качестве нелинейной преобразующей функции используется сигмоидная функция, то вместо последних двух выражений удобно использовать следующие рекуррентные формулы для выходного слоя:
k-1 j = (d j - y j) y j (1- y j) , E/W k-1 ij = k-1 j u k-1 i
для скрытых слоев:
k-1 j = [ k j w k ] u j k (1- u j k) , E/W k-1 ij = k-1 j u k-1 i
Эти соотношения называются формулами обратного распространения ошибки (Back-Propagation). Если при прямом функционировании входной сигнал распространяется по сети от входного слоя к выходному, то при подстройке весов ошибка сети распространяется от выходного слоя ко входному.
Обучение сетей Кохонена (построение карт признаков).
Для построения карты Кохонена требуется достаточно представительная выборка обучающих векторов признаков (U). Пусть каждый вектор U множества(U) имеет размерность k: U=(U 1 , U 2 , . . . ,U k).
Тогда первый (распределительный) слой сети Кохонена должен иметь k нейронов; n нейронов второго слоя (карты) располагаются из плоскости в какой-либо регулярной конфигурации, например из квадратной прямоугольной сетке (рис.3.3). Настраиваемым связям между нейронами первого и второго слоев W ij присваиваются случайные значения.
Здесь, индекс i обозначает номер нейрона первого слоя, индекс j - номер нейрона второго слоя. До начала обучения задают функцию влияния нейронов второго слоя друг на друга g(r,t) , где r- расстояние между нейронами, t- параметр, характеризующий время обучения.
Эта функция традиционно имеет вид "мексиканской шляпы" (рис.3.4.), которую в процессе обучения, по мере увеличения параметра t, делают более "узкой" . Однако часто используют более простые функции, например:

где: D - константа, характеризующая начальный радиус положительного пика "мексиканской шляпы".
Каждый цикл обучения заключается в поочередном предъявлении сети векторов обучающего множества с последующей корректировкой весов W ij . Корректировка осуществляется следующим образом:
1. При появлении на входе сети очередного обучающего вектора U сеть вычисляет отклик нейронов второго слоя:

2. Выбирается нейрон-победитель (т.е. нейрон с наибольшим откликом). Его номер C определяется как:
C = argmax Y j , j=1,2, . . ., n.
3. Корректировка весов связей W осуществляется по следующей формуле:
W ij new = W ij old +g(r,t)(U i - W ij old), i=1, . . . ,k; j=1, . . . n.
Здесь - константа, характеризующая обучение.
Если после очередного цикла обучения процесс изменения весов замедлился, увеличивают параметр t.
Обучение сетей Хопфилда.
Здесь следует выделить две возможности, связанные с последующим использованием сети: будет ли она использоваться как ассоциативная память или для решения оптимизационной задачи.
Сеть используется как ассоциативная память. А именно: мы хотим хранить в ней m двоичных векторов V s , s=1,2, . . .n: V s =(V 1s ,V 2s ,...,V ns).
Это означает, что при предъявлении сети любого из этих векторов она должна прийти в устойчивое состояние, соответствующее этому вектору, т.е. на выходе нейронов должен выделиться этот же вектор. Если же сети будет предъявлен неизвестный ей вектор U , то на выходе сети должен появиться один из запомненных векторов V i , который наиболее близок к U.
Очевидно, количество нейронов в такой сети должно быть равно длине хранимых векторов n.
Простейший способ формирования весов такой сети достигается следующей процедурой :

Однако емкость такой сети (т.е. количество хранимых векторов m), невелика, m log n. В работе для формирования весов использовалось правило обучения Хеббовского типа, в результате чего была достигнута емкость сети m n.
Сеть используется для решения оптимизационной задачи. Такая возможность обусловлена следующим замечательным свойством сетей Хопфилда: в процессе функционирования сети величина (которую в литературе принято называть "энергией" сети Хопфилда), не возрастает. Один из вариантов "энергии" сети Хопфилда:

где A,B - константы, определяемые задачей. Задача исследования состоит в формулировке исходной оптимизационной проблемы в терминах нейросети и записи минимизируемого функционала E h . Полученное для W ij выражение дает значение весовых множителей. В результате функционирования сеть придает в равновесное состояние, которое соответствует локальному минимуму функционала E h . Величины возбужденности нейронов при этом соответствуют значениям аргументов, на которых достигается минимум.
Теперь, когда стало ясно, что именно мы хотим построить, мы можем переходить к вопросу "как строить такую нейронную сеть". Этот вопрос решается в два этапа: 1. Выбор типа (архитектуры) нейронной сети. 2. Подбор весов (обучение) нейронной сети. На первом этапе следует выбрать следующее: * какие нейроны мы хотим использовать (число входов, передаточные функции); * каким образом следует соединить их между собой; * что взять в качестве входов и выходов нейронной сети. Эта задача на первый взгляд кажется необозримой, но, к счастью, нам необязательно придумывать нейронную сеть "с нуля" - существует несколько десятков различных нейросетевых архитектур, причем эффективность многих из них доказана математически. Наиболее популярные и изученные архитектуры - это многослойный перцептрон, нейронная сеть с общей регрессией, нейронные сети Кохонена и другие. Про все эти архитектуры скоро можно будет прочитать в специальном разделе этого учебника.
На втором этапе нам следует "обучить" выбранную нейронную сеть, то есть подобрать такие значения ее весов, чтобы она работала нужным образом. Необученная нейронная сеть подобна ребенку - ее можно научить чему угодно. В используемых на практике нейронных сетях количество весов может составлять несколько десятков тысяч, поэтому обучение - действительно сложный процесс. Для многих архитектур разработаны специальные алгоритмы обучения, которые позволяют настроить веса нейронной сети определенным образом. Наиболее популярный из этих алгоритмов - метод обратного распространения ошибки (Error Back Propagation), используемый, например, для обучения перцептрона.
Обучение нейронных сетей
Обучить нейронную сеть - значит, сообщить ей, чего мы от нее добиваемся. Этот процесс очень похож на обучение ребенка алфавиту. Показав ребенку изображение буквы "А", мы спрашиваем его: "Какая это буква?" Если ответ неверен, мы сообщаем ребенку тот ответ, который мы хотели бы от него получить: "Это буква А". Ребенок запоминает этот пример вместе с верным ответом, то есть в его памяти происходят некоторые изменения в нужном направлении. Мы будем повторять процесс предъявления букв снова и снова до тех пор, когда все 33 буквы будут твердо запомнены. Такой процесс называют "обучение с учителем".
При обучении нейронной сети мы действуем совершенно аналогично. У нас имеется некоторая база данных, содержащая примеры (набор рукописных изображений букв). Предъявляя изображение буквы "А" на вход нейронной сети, мы получаем от нее некоторый ответ, не обязательно верный. Нам известен и верный (желаемый) ответ - в данном случае нам хотелось бы, чтобы на выходе нейронной сети с меткой "А" уровень сигнала был максимален. Обычно в качестве желаемого выхода в задаче классификации берут набор (1, 0, 0, ...), где 1 стоит на выходе с меткой "А", а 0 - на всех остальных выходах. Вычисляя разность между желаемым ответом и реальным ответом сети, мы получаем 33 числа - вектор ошибки. Алгоритм обратного распространения ошибки - это набор формул, который позволяет по вектору ошибки вычислить требуемые поправки для весов нейронной сети. Одну и ту же букву (а также различные изображения одной и той же буквы) мы можем предъявлять нейронной сети много раз. В этом смысле обучение скорее напоминает повторение упражнений в спорте - тренировку.
Оказывается, что после многократного предъявления примеров веса нейронной сети стабилизируются, причем нейронная сеть дает правильные ответы на все (или почти все) примеры из базы данных. В таком случае говорят, что "нейронная сеть выучила все примеры", "нейронная сеть обучена", или "нейронная сеть натренирована". В программных реализациях можно видеть, что в процессе обучения величина ошибки (сумма квадратов ошибок по всем выходам) постепенно уменьшается. Когда величина ошибки достигает нуля или приемлемого малого уровня, тренировку останавливают, а полученную нейронную сеть считают натренированной и готовой к применению на новых данных. Важно отметить, что вся информация, которую нейронная сеть имеет о задаче, содержится в наборе примеров. Поэтому качество обучения нейронной сети напрямую зависит от количества примеров в обучающей выборке, а также от того, насколько полно эти примеры описывают данную задачу.
Так, например, бессмысленно использовать нейронную сеть для предсказания финансового кризиса, если в обучающей выборке кризисов не представлено. Считается, что для полноценной тренировки нейронной сети требуется хотя бы несколько десятков (а лучше сотен) примеров. Повторим еще раз, что обучение нейронных сетей - сложный и наукоемкий процесс. Алгоритмы обучения нейронных сетей имеют различные параметры и настройки, для управления которыми требуется понимание их влияния.

После того, как нейронная сеть обучена, мы можем применять ее для решения полезных задач. Важнейшая особенность человеческого мозга состоит в том, что, однажды обучившись определенному процессу, он может верно действовать и в тех ситуациях, в которых он не бывал в процессе обучения. Например, мы можем читать почти любой почерк, даже если видим его первый раз в жизни. Так же и нейронная сеть, грамотным образом обученная, может с большой вероятностью правильно реагировать на новые, не предъявленные ей ранее данные. Например, мы можем нарисовать букву "А" другим почерком, а затем предложить нашей нейронной сети классифицировать новое изображение. Веса обученной нейронной сети хранят достаточно много информации о сходстве и различиях букв, поэтому можно рассчитывать на правильный ответ и для нового варианта изображения. Примеры готовых нейронных сетей
Описанные выше процессы обучения и применения нейронных сетей можно увидеть в действии прямо сейчас. Фирмой Ward Systems Group подготовлено несколько простых программ, которые написаны на основе библиотеки NeuroWindows. Каждая из программ позволяет пользователю самостоятельно задать набор примеров и обучить на этом наборе определенную нейронную сеть. Затем можно предлагать этой нейронной сети новые примеры и наблюдать ее работу.











