Нечеткая логика. Нечеткая логика на практике
Нечеткая логика (fuzzy logic) - это надмножество классической булевой логики. Она расширяет возможности классической логики, позволяя применять концепцию неопределенности в логических выводах. Употребление термина "нечеткий" применительно к математической теории может ввести в заблуждение. Более точно ее суть характеризовало бы название "непрерывная логика". Аппарат нечеткой логики столь же строг и точен, как и классический, но вместе со значениями "ложь" и "истина" он позволяет оперировать значениями в промежутке между ними. Говоря образно, нечеткая логика позволяет ощущать все оттенки окружающего мира, а не только чистые цвета.
Нечеткая логика как новая область математики была представлена в 60-х годах профессором калифорнийского университета Лотфи Заде (Lotfi Zadeh). Первоначально она разрабатывалась как средство моделирования неопределенности естественного языка, однако впоследствии круг задач, в которых нечеткая логика нашла применение, значительно расширился. В настоящее время она используется для управления линейными и нелинейными системами реального времени, при решении задач анализа данных, распознавания, исследования операций.
Часто для иллюстрации связи нечеткой логики с естественными представлениями человека об окружающем мире приводят пример о пустыне. Определим понятие "пустыня" как "бесплодная территория, покрытая песком". Теперь рассмотрим простейшее высказывание: "Сахара - это пустыня". Нельзя не согласиться с ним, принимая во внимание данное выше определение. Предположим, что с поверхности Сахары удалена одна песчинка. Осталась ли Сахара пустыней? Скорее всего, да. Продолжая удалять песчинки одну за другой, всякий раз оцениваем справедливость приведенного ранее высказывания. По прошествии определенного промежутка времени песка в Сахаре не останется и высказывание станет ложным. Но после какой именно песчинки его истинность меняется? В реальной жизни с удалением одной песчинки пустыня не исчезает. Пример показывает, что традиционная логика не всегда согласуется с представлениями человека. Для оценки степени истинности высказываний естественный язык имеет специальные средства (некоторые наречия и обороты, например: "в некоторой степени", "очень" и др.). С возникновением нечеткой логики они появились и в математике.
Одно из базовых понятий традиционной логики - понятие подмножества. Подобно этому в основе нечеткой логики лежит теория нечетких подмножеств (нечетких множеств). Эта теория занимается рассмотрением множеств, определяемых небинарными отношениями вхождения. Это означает, что принимается во внимание не просто то, входит элемент во множество или не входит, но и степень его вхождения, которая может изменяться от 0 до 1.
Пусть S - множество с конечным числом элементов, S ={s 1 , s 2 ,..., s n }, где n - число элементов (мощность) множества S . В классической теории множеств подмножество U множества S может быть определено как отображение элементов S на множество В = {0, 1}:
U: S => В.
Это отображение может быть представлено множеством упорядоченных пар вида:
{s i ,m ui }, iÎ,
где s i - i-й элемент множества S ; n - мощность множества S ; m Ui - элемент множества В = {0, 1}. Если m Ui = 1, то s i является элементом подмножества U . Элемент "0" множества В используется для обозначения того, что s i не входит в подмножество U . Проверка истинности предиката "s k ÎU " осуществляется путем нахождения пары, в которой s k - первый элемент. Если для этой пары m Uk =l, то значением предиката будет "истина", в противном случае - "ложь".
Если U - подмножество S , то U может быть представлено n-мерным вектором (m U 1 , m U 2 ,…, m Un), где i-й элемент вектора равен "1", если соответствующий элемент множества S входит и в U , и "0" в противном случае. Таким образом, U может быть однозначно представлено точкой в n-мерном бинарном гиперкубе В n , В = {0, 1} (рисунок 1).
Рисунок 1 - Графическое представление традиционного множества
Нечеткое подмножество F может быть представлено как отображение элементов множества S на интервал I = . Это отображение определяется множеством упорядоченных пар: {s i ,m F ,(s i)}, iÎ, где s i - i-й элемент множества S ; n - мощность множества S ; m F (s i) Î -степень вхождения элемента s i в множество F . Значение m F (s i), равное 1, означает полное вхождение, m F (s i) = 0 указывает на то, что элемент s i не принадлежит множеству F . Часто отображение задается функцией m F (x) принадлежности х нечеткому множеству F . В силу этого термины "нечеткое подмножество" и "функция принадлежности" употребляются как синонимы. Степень истинности предиката "s k ÎF " определяется путем нахождения парного элементу s k значения m F (s k), определяющего степень вхождения s k в F .
Обобщая геометрическую интерпретацию традиционного подмножества на нечеткий случай, получаем представление F точкой в гиперкубе I n , I = . В отличие от традиционных подмножеств точки, изображающие нечеткие подмножества, могут находиться не только на вершинах гиперкуба, но и внутри него (рисунок 2).

Рисунок 2 - Графическое представление нечеткого множества
Рассмотрим пример определения нечеткого подмножества. Имеется множество всех людей S . Определим нечеткое подмножество Т всех высоких людей этого множества. Введем для каждого человека степень его принадлежности подмножеству Т . Для этого зададим функцию принадлежности m Т (h), определяющую, в какой степени можно считать высоким человека ростом h сантиметров.
 (1)
(1)
где h - рост конкретного человека в сантиметрах.
График этой функции представлен на рисунке 3.

Рисунок 3 - График функции принадлежности rn T (h)
Пусть рост Михаила - 163 см, тогда истинность высказывания "Михаил высок" будет равна 0.21. Использованная в данном случае функция принадлежности тривиальна. При решении большинства реальных задач подобные функции имеют более сложный вид, кроме того, число их аргументов может быть большим.
Методы построения функций принадлежности для нечетких подмножеств довольно разнообразны. В большинстве случаев они отражают субъективные представления экспертов о предметной области. Так, например, кому-то человек ростом 180 см может показаться высоким, а кому-то - нет. Однако часто такая субъективность помогает снизить степень неопределенности при решении слабо формализованных задач. Как правило, для задания функций принадлежности используются типовые зависимости, параметры которых определяются путем обработки мнений экспертов. Представление произвольных функций при реализации автоматизированных систем часто затруднено, поэтому в реальных разработках такие зависимости аппроксимируются кусочно-линейными функциями.
Необходимо осознавать разницу между нечеткой логикой и теорией вероятностей. Заключается она в различии понятий вероятности и степени принадлежности. Вероятность определяет, насколько возможен один из нескольких взаимоисключающих исходов или одно из множества значений. Например, может определяться вероятность того, что утверждение истинно. Утверждение может быть либо истинным, либо ложным. Степень принадлежности показывает, насколько то или иное значение принадлежит определенному классу (подмножеству). Например, при определении истинности утверждения ее возможные значения не ограничены "ложью" и "истиной", а могут попадать и в промежуток между ними. Еще одно различие выражено в математических свойствах этих понятий. В отличие от вероятности для степени принадлежности не требуется выполнение аксиомы аддитивности.
Математическая теория нечетких множеств (fuzzy sets) инечеткая логика (fuzzy logic ) являются обобщениями классическойтеории множеств и классической формальной логики. Данные понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой теории стало наличие нечетких иприближенных рассуждений при описании человеком процессов, систем, объектов.
Одной из основных характеристик нечеткой логики является лингвистическая переменная, которая определяется набором вербальных (словесных) характеристик некоторого свойства. Рассмотрим лингвистическую переменную «скорость», которую можно характеризовать через набор следующих понятий-значений: «малая», «средняя» и «большая», данные значения называются термами.
Следующей основополагающей характеристикой нечеткой логики является понятие функции принадлежности. Функция принадлежности определяет, насколько мы уверены в том, что данное значение лингвистической переменной (например, скорость) можно отнести к соответствующим ей категориям (в частности для лингвистической переменной скорость к категориям «малая», «средняя», «большая»).
На следующем рисунке (первая часть) отражено, как одни и те же значения лингвистической переменной могут соответствовать различным понятиям-значениям или термам. Тогда функции принадлежности, характеризующие нечеткие множества понятий скорости, можно выразить графически, в более привычном математическом виде (рис. 35, вторая часть).

Из рисунка видно, что степень, с которой численное значение скорости, например v = 53, совместимо с понятием «большая», есть 0,7, в то время как совместимость значений скорости, равных 48 и 45, с тем же понятием есть 0,5 и 0,1 соответственно.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
Треугольная функция принадлежности определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:

При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a,b,c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):

При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
 Рисунок
1. Типовые кусочно-линейные
функции
принадлежности.
Рисунок
1. Типовые кусочно-линейные
функции
принадлежности.
Функция принадлежности гауссова типа описывается формулой
![]()
и оперирует двумя параметрами. Параметр c обозначает центр нечеткого множества, а параметр отвечает за крутизну функции.
 Рисунок
2. Гауссова функция принадлежности.
Рисунок
2. Гауссова функция принадлежности.
Совокупность функций принадлежности для каждого терма из базового терм-множества T обычно изображаются вместе на одном графике. На рисунке приведен пример описанной лингвистической переменной "Цена акции".
 Рис.
Описание лингвистической переменной
"Цена акции".
Рис.
Описание лингвистической переменной
"Цена акции".
Количество термов в лингвистической переменной редко превышает 7.
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме "Если-то" и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
Существует хотя бы одно правило для каждого лингвистического терма выходной переменной .
Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида: R 1: ЕСЛИ x 1 это A 11 … И … x n это A 1n , ТО y это B 1 … R i: ЕСЛИ x 1 это A i1 … И … x n это A in , ТО y это B i … R m: ЕСЛИ x 1 это A i1 … И … x n это A mn , ТО y это B m , где x k , k=1..n – входные переменные; y – выходная переменная; A ik – термы соответствующих переменных с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y * на основе заданных четких значений x k , k=1..n.
В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация (см. рисунок 5).
 Рисунок
5. Система нечеткого логического вывода.
Рисунок
5. Система нечеткого логического вывода.
Алгоритмы нечеткого вывода различаются главным образом видом используемых правил, логических операций и разновидностью метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Рассмотрим подробнее нечеткий вывод на примере механизма Мамдани (Mamdani). Это наиболее распространенный способ логического вывода в нечетких системах. В нем используется минимаксная композиция нечетких множеств. Данный механизм включает в себя следующую последовательность действий.
Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок). Для базы правил с m правилами обозначим степени истинности как A ik (x k), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни "отсечения" для левой части каждого из правил:
![]()
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:
![]()
где MF(y) – функция принадлежности итогового нечеткого множества.
4. Дефазификация, или приведение к четкости. Под дефаззификацией понимается процедура преобразования нечетких величин, получаемых в результате нечеткого вывода, в четкие. Эта процедура является необходимой в тех случаях, где требуется интерпретация нечетких выводов конкретными четкими величинами, т.е. когда на основе функции принадлежности возникает потребность определить для каждой точки вZ числовые значения.
В настоящее время отсутствует систематическая процедура выбора стратегии дефаззификации. На практике часто используют два наиболее общих метода: метод центра тяжести (ЦТ - центроидный), метод максимума (ММ).
Для дискретных пространств в центроидном методе формула для вычисления четкого значения выходной переменной представляется в следующем виде:
Стратегия дефаззификации ММ предусматривает подсчет всех тех z , чьи функции принадлежности достигли максимального значения. В этом случае (для дискретного варианта) получим
где z - выходная переменная, для которой функция принадлежности достигла максимума;m - число таких величин.
Из этих двух наиболее часто используемых стратегий дефаззификации, стратегия ММ дает лучшие результаты для переходного режима, аЦТ - в установившемся режиме из-за меньшей среднеквадратической ошибки.
Пример нечеткого правила

Как работает.
По максимальному значению функций принадлежности (для скорости 60 км в час значение функции принадлежности «низкая» = 0, а для дорожных условий 75 % от нормы значение функции принадлежности «тяжелые» = около 0.7) по 0.7 проводится прямая которая рассекает геометрическую фигуру заключения (подача топлива) на две части, в результате берется фигура лежащая ниже прямой а верхняя часть отбрасывается. Это для одного правила, таких правил может быть 100 и более в реальных задачах.
Рассмотрим процесс получения нечеткого вывода по трем правилам одновременно с последующим получением четкого решения. Данная процедура включает в себя три этапа. На первом этапе получают нечеткие выводы по каждому из правил в отдельности по схеме, показанной на рис. 3.13. На втором этапе производится сложение результирующих функций, полученных на предыдущем этапе (применяется логическая операция ИЛИ, т.е. берется максимум). Третий этап - этап получения четкого решения (дефаззификация). Здесь применяется любой из известных классических методов: метод центра тяжести и т.д. Полученное в виде числового значения четкое решение служит задающей величиной системы управления. В нашем примере это будет величина, в соответствии с которой ИСУ должна будет изменить подачу топлива. Процесс получения нечетких выводов по нескольким правилам с последующей дефаззификацией для рассматриваемого примера показан на рис. 3.14. При начальном значении скорости = 65 км в час, и дорожным условиям = 80 % от норматива получаем следующую схему решения об уровне подачи топлива.

Рис. 3.14. Процесс получения нечетких выводов по правилам и их преобразование в четкое решение.
Как видно из рис. 3.14, в результате дефаззификации получено четкое решение: при заданных значениях скорости и дорожных условий подача топлива должна составлять 63% от
максимального значения. Таким образом, несмотря на нечеткость выводов, в итоге получено вполне четкое и определенное решение. Такое решение, вероятно, принял бы и водитель автомобиля в процессе движения. Данный пример демонстрирует великолепные возможности моделирования человеческих рассуждений на основе методов теории нечетких множеств.
Эпименид Кносский с острова Крит – полумифический поэт и философ, живший в VI в. до н.э., однажды заявил: «Все критяне – лжецы!». Так как он и сам был критянином, то его помнят как изобре тателя так называемого критского парадокса.
В терминах аристотелевой логики, в которой утверждение не может быть одновременно истинным и ложным, и подобные самоотрицания не имеют смысла. Если они истинны, то они ложны, но если они ложны, то они истинны.
И здесь на сцену выходит нечеткая логика, где переменные могут быть частичными членами множеств. Истинность или ложность перестают быть абсолютными – утверждения могут быть частично истинными и частично ложными. Использование подобного подхода позволяет строго математически доказать, что парадокс Эпименида ровно на 50% истинен и на 50% ложен.
Таким образом, нечеткая логика в самой своей основе несовместима с аристотелевой логикой, особенно в отношении закона Tertium non datur («Третьего не дано» – лат.), который также называют законом исключения среднего1
. Если сформулировать его кратко, то звучит он так: если утверждение не является истинным, то оно является ложным. Эти постулаты настолько базовые, что их часто просто принимают на веру.
Более банальный пример пользы нечеткой логики можно привести в контексте концепции холода. Большинство людей способно ответить на вопрос: «Холодно ли вам сейчас?». В большинстве случаев (если вы разговариваете не с аспирантом-физиком) люди понимают, что речь не идет об абсолютной температуре по шкале Кельвина. Хотя температуру в 0 K можно, без сомнения, назвать холодом, но температуру в +15 C многие холодом считать не будут.
Но машины не способны проводить такую тонкую градацию. Если стандартом определения холода будет «температура ниже +15 C», то +14,99 C будет расцениваться как холод, а +15 C – не будет.
Теория нечетких множеств
Рассмотрим рис. 1. На нем представлен график, помогающий понять то, как человек воспринимает температуру. Температуру в +60 F (+12 C) человек воспринимает как холод, а температуру в +80 F (+27 C) – как жару. Температура в +65 F (+15 C) одним кажется низкой, другим – достаточно комфортной. Мы называем эту группу определений функцией принадлежности к множествам,описывающим субъективное восприятие температуры человеком.
Так же просто можно создать дополнительные множества, описывающие восприятие температуры человеком. Например, можно добавить такие множества, как «очень холодно» и «очень жарко». Можно описать подобные функции для других концепций, например, для состояний «открыто» и «закрыто», температуры в охладителе или температуры в башенном охладителе.
То есть нечеткие системы можно использовать как универсальный аппроксиматор (усреднитель) очень широкого класса линейных и нелинейных систем. Это не только делает более надежными стратегии контроля в нелинейных случаях, но и позволяет использовать оценки специалистов-экспертов для построения схем компьютерной логики.
Нечеткие операторы
Чтобы применить алгебру для работы с нечеткими значениями, нужно определить используемых операторов. Обычно в булевой логике используется лишь ограниченный набор операторов, с помощью которых и производится выполнение других операций: NOT (оператор «НЕ»), AND (оператор «И») и OR (оператор «ИЛИ»).
Можно дать множество определений для этих трех базовых операторов, три из которых приведены в таблице. Кстати, все определения одинаково справедливы для булевой логики (для проверки просто подставьте в них 0 и 1). В булевой логике значение FALSE («ЛОЖЬ») эквивалентно значению «0», а значение TRUE («ИСТИНА») эквивалентно значению «1». Аналогичным образом в нечеткой логике степень истинности может меняться в диапазоне от 0 до 1, поэтому значение «Холод» верно в степени 0,1, а операция NOT(«Холод») даст значение 0,9.
Вы можете вернуться к парадоксу Эпименида и постараться его решить (математически он выражается как A = NOT(A), где A – это степень истинности соответствующего утверждения). Если же вы хотите более сложную задачу, то попробуйте решить вопрос о звуке хлопка, производимого одной рукой…
Решение задач методами нечеткой логики
Лишь немногие клапаны способны открываться «чуть-чуть». При работе оборудования обычно используются четкие значения (например, в случае бимодального сигнала 0-10 В), которые можно получить, используя так называемое «решение задач методами нечеткой логики». Подобный подход позволяет преобразовать семантические знания, содержащиеся в нечеткой системе, в реализуемую стратегию управления2.
Это можно сделать с использованием различных методик, но для иллюстрации процесса в целом рассмотрим всего один пример.
В методе height defuzzification результатом является сумма пиков нечетких множеств, рассчитываемая с использованием весовых коэффициентов. У этого метода есть несколько недостатков, включая плохую работу с несимметричными функциями принадлежности к множествам, но у него есть одно преимущество – этот метод наиболее простой для понимания.
Предположим, что набор правил, управляющих открытием клапана, даст нам следующий результат:
«Клапан частично закрыт»: 0,2
«Клапан частично открыт»: 0,7
«Клапан открыт»: 0,3
Если мы используем метод height defuzzification для определения степени открытости клапана, то получим результат:
«Клапан закрыт»: 0,1
(0,1*0% + 0,2*25% + 0,7*75% + 0,3*100%)/ /(0,1 + 0,2 + 0,7 + 0,3) =
= (0% + 5% + 52,5% + 30%)/(1,3) = = 87,5/1,3 = = 67,3%,
т.е. клапан необходимо открыть на 67,3%.
Практическое применение нечеткой логики
Когда только появилась теория нечеткой логики, в научных журналах можно было найти статьи, посвященные ее возможным областям применения. По мере продвижения разработок в данной области число практических применений для нечеткой логики начало быстро расти. В настоящее время этот список был бы слишком длинным, но вот несколько примеров, которые помогут понять, насколько широко нечеткая логика используется в системах управления и в экспертных системах3.
– Устройства для автоматического поддержания скорости движения автомобиля и увеличения эффективности/стабильности работы автомобильный двигателей (компании Nissan, Subaru).
Математическая теория нечетких множеств (fuzzy sets) и нечеткая логика (fuzzy logic) являются обобщениями классической теории множеств и классической формальной логики. Данные понятия были впервые предложены американским ученым Лотфи Заде (Lotfi Zadeh) в 1965 г. Основной причиной появления новой теории стало наличие нечетких и приближенных рассуждений при описании человеком процессов, систем, объектов.
Прежде чем нечеткий подход к моделированию сложных систем получил признание во всем мире, прошло не одно десятилетие с момента зарождения теории нечетких множеств. И на этом пути развития нечетких систем принято выделять три периода.
Первый период (конец 60-х–начало 70 гг.) характеризуется развитием теоретического аппарата нечетких множеств (Л. Заде, Э. Мамдани, Беллман). Во втором периоде (70–80-е годы) появляются первые практические результаты в области нечеткого управления сложными техническими системами (парогенератор с нечетким управлением). Одновременно стало уделяться внимание вопросам построения экспертных систем, построенных на нечеткой логике, разработке нечетких контроллеров. Нечеткие экспертные системы для поддержки принятия решений находят широкое применение в медицине и экономике. Наконец, в третьем периоде, который длится с конца 80-х годов и продолжается в настоящее время, появляются пакеты программ для построения нечетких экспертных систем, а области применения нечеткой логики заметно расширяются. Она применяется в автомобильной, аэрокосмической и транспортной промышленности, в области изделий бытовой техники, в сфере финансов, анализа и принятия управленческих решений и многих других.
Триумфальное шествие нечеткой логики по миру началось после доказательства в конце 80-х Бартоломеем Коско знаменитой теоремы FAT (Fuzzy Approximation Theorem). В бизнесе и финансах нечеткая логика получила признание после того как в 1988 году экспертная система на основе нечетких правил для прогнозирования финансовых индикаторов единственная предсказала биржевой крах. И количество успешных фаззи-применений в настоящее время исчисляется тысячами.
Математический аппарат
Характеристикой нечеткого множества выступает функция принадлежности (Membership Function). Обозначим через MF c (x) – степень принадлежности к нечеткому множеству C, представляющей собой обобщение понятия характеристической функции обычного множества. Тогда нечетким множеством С называется множество упорядоченных пар вида C={MF c (x)/x}, MF c (x) . Значение MF c (x)=0 означает отсутствие принадлежности к множеству, 1 – полную принадлежность.
Проиллюстрируем это на простом примере. Формализуем неточное определение "горячий чай". В качестве x (область рассуждений) будет выступать шкала температуры в градусах Цельсия. Очевидно, что она будет изменяется от 0 до 100 градусов. Нечеткое множество для понятия "горячий чай" может выглядеть следующим образом:
C={0/0; 0/10; 0/20; 0,15/30; 0,30/40; 0,60/50; 0,80/60; 0,90/70; 1/80; 1/90; 1/100}.
Так, чай с температурой 60 С принадлежит к множеству "Горячий" со степенью принадлежности 0,80. Для одного человека чай при температуре 60 С может оказаться горячим, для другого – не слишком горячим. Именно в этом и проявляется нечеткость задания соответствующего множества.
Для нечетких множеств, как и для обычных, определены основные логические операции. Самыми основными, необходимыми для расчетов, являются пересечение и объединение.
Пересечение двух нечетких множеств (нечеткое "И"): A B: MF AB (x)=min(MF A (x), MF B (x)).
Объединение двух нечетких множеств (нечеткое "ИЛИ"): A B: MF AB (x)=max(MF A (x), MF B (x)).
В теории нечетких множеств разработан общий подход к выполнению операторов пересечения, объединения и дополнения, реализованный в так называемых треугольных нормах и конормах. Приведенные выше реализации операций пересечения и объединения – наиболее распространенные случаи t-нормы и t-конормы.
Для описания нечетких множеств вводятся понятия нечеткой и лингвистической переменных.
Нечеткая переменная описывается набором (N,X,A), где N – это название переменной, X – универсальное множество (область рассуждений), A – нечеткое множество на X.
Значениями лингвистической переменной могут быть нечеткие переменные, т.е. лингвистическая переменная находится на более высоком уровне, чем нечеткая переменная. Каждая лингвистическая переменная состоит из:
- названия;
- множества своих значений, которое также называется базовым терм-множеством T. Элементы базового терм-множества представляют собой названия нечетких переменных;
- универсального множества X;
- синтаксического правила G, по которому генерируются новые термы с применением слов естественного или формального языка;
- семантического правила P, которое каждому значению лингвистической переменной ставит в соответствие нечеткое подмножество множества X.
Рассмотрим такое нечеткое понятие как "Цена акции". Это и есть название лингвистической переменной. Сформируем для нее базовое терм-множество, которое будет состоять из трех нечетких переменных: "Низкая", "Умеренная", "Высокая" и зададим область рассуждений в виде X= (единиц). Последнее, что осталось сделать – построить функции принадлежности для каждого лингвистического терма из базового терм-множества T.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
Треугольная функция принадлежности определяется тройкой чисел (a,b,c), и ее значение в точке x вычисляется согласно выражению:
$$MF\,(x) = \,\begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b &\ \\ 1\,-\,\frac{x\,-\,b}{c\,-\,b},\,b\leq \,x\leq \,c &\ \\ 0, \;x\,\not \in\,(a;\,c)\ \end{cases}$$
При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a,b,c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a,b,c,d):
$$MF\,(x)\,=\, \begin{cases} \;1\,-\,\frac{b\,-\,x}{b\,-\,a},\,a\leq \,x\leq \,b & \\ 1,\,b\leq \,x\leq \,c & \\ 1\,-\,\frac{x\,-\,c}{d\,-\,c},\,c\leq \,x\leq \,d &\\ 0, x\,\not \in\,(a;\,d) \ \end{cases}$$
При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
Функция принадлежности гауссова типа описывается формулой
$$MF\,(x) = \exp\biggl[ -\,{\Bigl(\frac{x\,-\,c}{\sigma}\Bigr)}^2\biggr]$$
и оперирует двумя параметрами. Параметр c обозначает центр нечеткого множества, а параметр отвечает за крутизну функции.

Совокупность функций принадлежности для каждого терма из базового терм-множества T обычно изображаются вместе на одном графике. На рисунке 3 приведен пример описанной выше лингвистической переменной "Цена акции", на рисунке 4 – формализация неточного понятия "Возраст человека". Так, для человека 48 лет степень принадлежности к множеству "Молодой" равна 0, "Средний" – 0,47, "Выше среднего" – 0,20.
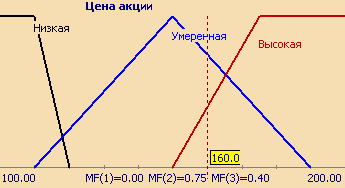

Количество термов в лингвистической переменной редко превышает 7.
Нечеткий логический вывод
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме "Если-то" и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
- Существует хотя бы одно правило для каждого лингвистического терма выходной переменной.
- Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида:
R 1: ЕСЛИ x 1 это A 11 … И … x n это A 1n , ТО y это B 1
…
R i: ЕСЛИ x 1 это A i1 … И … x n это A in , ТО y это B i
…
R m: ЕСЛИ x 1 это A i1 … И … x n это A mn , ТО y это B m ,
где x k , k=1..n – входные переменные; y – выходная переменная; A ik – заданные нечеткие множества с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y * на основе заданных четких значений x k , k=1..n.
В общем случае механизм логического вывода включает четыре этапа: введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация (см. рисунок 5).
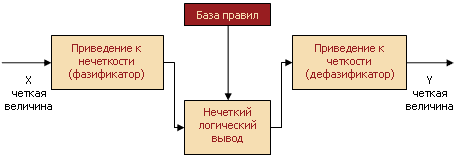
Алгоритмы нечеткого вывода различаются главным образом видом используемых правил, логических операций и разновидностью метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Рассмотрим подробнее нечеткий вывод на примере механизма Мамдани (Mamdani). Это наиболее распространенный способ логического вывода в нечетких системах. В нем используется минимаксная композиция нечетких множеств. Данный механизм включает в себя следующую последовательность действий.
- Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок). Для базы правил с m правилами обозначим степени истинности как A ik (x k), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни "отсечения" для левой части каждого из правил:
$$alfa_i\,=\,\min_i \,(A_{ik}\,(x_k))$$
$$B_i^*(y)= \min_i \,(alfa_i,\,B_i\,(y))$$
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
где MF(y) – функция принадлежности итогового нечеткого множества.
Дефазификация, или приведение к четкости. Существует несколько методов дефазификации. Например, метод среднего центра, или центроидный метод:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
Геометрический смысл такого значения – центр тяжести для кривой MF(y). Рисунок 6 графически показывает процесс нечеткого вывода по Мамдани для двух входных переменных и двух нечетких правил R1 и R2.
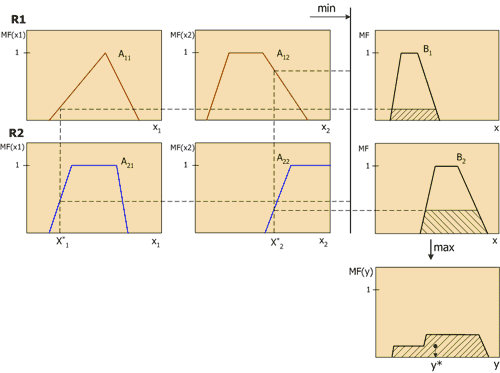
Интеграция с интеллектуальными парадигмами
Гибридизация методов интеллектуальной обработки информации – девиз, под которым прошли 90-е годы у западных и американских исследователей. В результате объединения нескольких технологий искусственного интеллекта появился специальный термин – "мягкие вычисления" (soft computing), который ввел Л. Заде в 1994 году. В настоящее время мягкие вычисления объединяют такие области как: нечеткая логика, искусственные нейронные сети, вероятностные рассуждения и эволюционные алгоритмы. Они дополняют друг друга и используются в различных комбинациях для создания гибридных интеллектуальных систем.
Влияние нечеткой логики оказалось, пожалуй, самым обширным. Подобно тому, как нечеткие множества расширили рамки классической математическую теорию множеств, нечеткая логика "вторглась" практически в большинство методов Data Mining, наделив их новой функциональностью. Ниже приводятся наиболее интересные примеры таких объединений.
Нечеткие нейронные сети
Нечеткие нейронные сети (fuzzy-neural networks) осуществляют выводы на основе аппарата нечеткой логики, однако параметры функций принадлежности настраиваются с использованием алгоритмов обучения НС. Поэтому для подбора параметров таких сетей применим метод обратного распространения ошибки, изначально предложенный для обучения многослойного персептрона. Для этого модуль нечеткого управления представляется в форме многослойной сети. Нечеткая нейронная сеть как правило состоит из четырех слоев: слоя фазификации входных переменных, слоя агрегирования значений активации условия, слоя агрегирования нечетких правил и выходного слоя.
Наибольшее распространение в настоящее время получили архитектуры нечеткой НС вида ANFIS и TSK. Доказано, что такие сети являются универсальными аппроксиматорами.
Быстрые алгоритмы обучения и интерпретируемость накопленных знаний – эти факторы сделали сегодня нечеткие нейронные сети одним из самых перспективных и эффективных инструментов мягких вычислений.
Адаптивные нечеткие системы
Классические нечеткие системы обладают тем недостатком, что для формулирования правил и функций принадлежности необходимо привлекать экспертов той или иной предметной области, что не всегда удается обеспечить. Адаптивные нечеткие системы (adaptive fuzzy systems) решают эту проблему. В таких системах подбор параметров нечеткой системы производится в процессе обучения на экспериментальных данных. Алгоритмы обучения адаптивных нечетких систем относительно трудоемки и сложны по сравнению с алгоритмами обучения нейронных сетей, и, как правило, состоят из двух стадий: 1. Генерация лингвистических правил; 2. Корректировка функций принадлежности. Первая задача относится к задаче переборного типа, вторая – к оптимизации в непрерывных пространствах. При этом возникает определенное противоречие: для генерации нечетких правил необходимы функции принадлежности, а для проведения нечеткого вывода – правила. Кроме того, при автоматической генерации нечетких правил необходимо обеспечить их полноту и непротиворечивость.
Значительная часть методов обучения нечетких систем использует генетические алгоритмы. В англоязычной литературе этому соответствует специальный термин – Genetic Fuzzy Systems.
Значительный вклад в развитие теории и практики нечетких систем с эволюционной адаптацией внесла группа испанских исследователей во главе с Ф. Херрера (F. Herrera).
Нечеткие запросы
Нечеткие запросы к базам данных (fuzzy queries) – перспективное направление в современных системах обработки информации. Данный инструмент дает возможность формулировать запросы на естественном языке, например: "Вывести список недорогих предложений о съеме жилья близко к центру города", что невозможно при использовании стандартного механизма запросов. Для этой цели разработана нечеткая реляционная алгебра и специальные расширения языков SQL для нечетких запросов. Большая часть исследований в этой области принадлежит западноевропейским ученым Д. Дюбуа и Г. Праде.
Нечеткие ассоциативные правила
Нечеткие ассоциативные правила (fuzzy associative rules) – инструмент для извлечения из баз данных закономерностей, которые формулируются в виде лингвистических высказываний. Здесь введены специальные понятия нечеткой транзакции, поддержки и достоверности нечеткого ассоциативного правила.
Нечеткие когнитивные карты
Нечеткие когнитивные карты (fuzzy cognitive maps) были предложены Б. Коско в 1986 г. и используются для моделирования причинных взаимосвязей, выявленных между концептами некоторой области. В отличие от простых когнитивных карт, нечеткие когнитивные карты представляют собой нечеткий ориентированный граф, узлы которого являются нечеткими множествами. Направленные ребра графа не только отражают причинно-следственные связи между концептами, но и определяют степень влияния (вес) связываемых концептов. Активное использование нечетких когнитивных карт в качестве средства моделирования систем обусловлено возможностью наглядного представления анализируемой системы и легкостью интерпретации причинно-следственных связей между концептами. Основные проблемы связаны с процессом построения когнитивной карты, который не поддается формализации. Кроме того, необходимо доказать, что построенная когнитивная карта адекватна реальной моделируемой системе. Для решения данных проблем разработаны алгоритмы автоматического построения когнитивных карт на основе выборки данных.
Нечеткая кластеризация
Нечеткие методы кластеризации, в отличие от четких методов (например, нейронные сети Кохонена), позволяют одному и тому же объекту принадлежать одновременно нескольким кластерам, но с различной степенью. Нечеткая кластеризация во многих ситуациях более "естественна", чем четкая, например, для объектов, расположенных на границе кластеров. Наиболее распространены: алгоритм нечеткой самоорганизации c-means и его обобщение в виде алгоритма Густафсона-Кесселя.
Литература
- Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений. – М.: Мир, 1976.
- Круглов В.В., Дли М.И. Интеллектуальные информационные системы: компьютерная поддержка систем нечеткой логики и нечеткого вывода. – М.: Физматлит, 2002.
- Леоленков А.В. Нечеткое моделирование в среде MATLAB и fuzzyTECH. – СПб., 2003.
- Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. – М., 2004.
- Масалович А. Нечеткая логика в бизнесе и финансах. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. Fuzzy systems as universal approximators // IEEE Transactions on Computers, vol. 43, No. 11, November 1994. – P. 1329-1333.
- Cordon O., Herrera F., A General study on genetic fuzzy systems // Genetic Algorithms in engineering and computer science, 1995. – P. 33-57.
Нечеткая логика (fuzzy logic )возникла как наиболее удобный способ построения сложными технологическими процессами, а также нашла применение в бытовой электронике, диагностических и других экспертных системах. Математический аппарат нечеткой логики впервые был разработан в США в середине 60-х годов прошлого века, активное развитие данного метода началось и в Европе.
Классическая логика развивается с древнейших времен. Ее основоположником считается Аристотель. Логика известна нам как строгая наука, имеющая множество прикладных применений: например, именно на положениях классической (булевой) логики основан принцип действия всех современных компьютеров. Вместе с тем классическая логика имеет один существенный недостаток - с ее помощью невозможно адекватно описать ассоциативное мышление человека. Классическая логика оперирует только двумя понятиями: ИСТИНА и ЛОЖЬ (логические 1 или 0), и исключая любые промежуточные значения. Все это хорошо для вычислительных машин, но попробуйте представить весь окружающий вас мир только в черном и белом цвете, вдобавок исключив из языка любые ответы на вопросы, кроме ДА и НЕТ. В такой ситуации вам можно только посочувствовать.
Традиционная математика с ее точными и однозначными формулировками закономерностей также имеет в своей основе классическую логику. А поскольку именно математика, в свою очередь, представляет собой универсальный инструмент для описания явлений окружающего мира во всех естественных науках (физика, химия, биология и т. д.) и их прикладных приложениях (например, теория измерений, теория управления и т. д.), неудивительно все эти науки оперируют математически точными данными, такими как: «средняя скорость автомобиля на участке пути длиной 62 км равнялась 93 км/ч». Но мыслит ли в действительности человек такими категориями? Представим, что в вашей машине вышел из строя спидометр. Означает ли это, что отныне вы лишены возможности оценивать скорость вашего перемещения и не в состоянии ответить на вопросы типа «быстро ли ты доехал вчера домой?». Разумеется нет. Скорее всего вы скажете в ответ что-то вводе: «Да, довольно быстро». Собственно говоря, вы скорее всего ответите примерно в том же духе, даже и в том случае, если спидометр вашей машины был в полном порядке, поскольку, совершая поездки, не имеете привычки непрерывно отслеживать его показания в режиме реального времени. То есть, в своем естественном мышлении применительно к скорости мы склонны оперировать не точными значениями в км/ч или м/с, а приблизительными оценками типа: «медленно», «средне», «быстро» и бесчисленным множеством полутонов и промежуточных оценок: «тащился как черепаха», «катился, не торопясь», «не выбивался из потока», «ехал довольно быстро», «несся как ненормальный» и т. п.
Если попытаться выразить наши интуитивные понятия о скорости графически, то получится нечто вроде рисунка ниже.
Здесь по оси X отложены значения скорости в традиционной строгой математической записи, а по оси Y – т. н. функцию принадлежности (изменяется от 0 до 1) точного значения скорости к нечеткому множеству , обозначенному тем или иным значением лингвистической переменной «скорость»: очень низкая, низкая, средняя, высокая и очень высокая. Этих градаций (гранул) может быть меньше или больше. Чем больше гранулированность нечеткой информации, тем больше она приближается к математически точной оценке (не забудем, что и выраженная в традиционной форме измерительная информация всегда обладает некоторой погрешностью, а значит в определенном смысле также является нечеткой). Таким образом, например значение скорости 105 км/ч принадлежит к нечеткому множеству «высокая» со значением функции принадлежности 0.8, а к множеству «очень высокая» со значением 0.5.
Другой пример – оценка возраста человека. Часто мы не имеем абсолютно точной информации о возрасте того или иного знакомого нам человека и поэтому, отвечая на соответствующий вопрос, вынуждены давать нечеткую оценку типа: «ему лет 30» или «ему далеко за 60» и т. п. Особенно часто используются такие значения лингвистической переменной «возраст» как: «молодой», «средних лет», «старый» и т. п. На рисунке ниже приведен графически возможный вид нечеткого множества «возраст = молодой» (очевидно, с точки зрения человека, которому самому ну никак не больше 20 лет;)

Нечеткие числа, получаемые в результате “не вполне точных измерений”, во многом похожи (но не тождественны! см. пример с двумя бутылками) распределениям теории вероятностей, но свободны от присущих последним недостатков: малое количество пригодных к анализу функций распределения, необходимость их принудительной нормализации, соблюдение требований аддитивности, трудность обоснования адекватности математической абстракции для описания поведения фактических величин. По сравнению с точными и, тем более, вероятностными методами, нечеткие методы измерения и управления позволяют резко сократить объем производимых вычислений, что, в свою очередь, приводит к увеличению быстродействия нечетких систем.
Как уже говорилось, принадлежность каждого точного значения к одному из значений лингвистической переменной определяется посредством функции принадлежности. Ее вид может быть абсолютно произвольным. Сейчас сформировалось понятие о так называемых стандартных функциях принадлежности (см. рисунок ниже).

Стандартные функции принадлежности легко применимы к решению большинства задач. Однако если предстоит решать специфическую задачу, можно выбрать и более подходящую форму функции принадлежности, при этом можно добиться лучших результатов работы системы, чем при использовании функций стандартного вида.
Процесс построения (графического или аналитического) функции принадлежности точных значений к нечеткому множеству называется фаззификацией данных.











